数据库学习
安装配置mysql不想写
mysql语法介绍
sql语句可以单行或多行,分号结尾
可缩进
不区分大小写,关键字建议大写
注释
– 单行注释
# mysql特有单行注释
/* 多行注释 */DDL 数据定义语言,定义数据库对象(数据库,表,字段)
DML 数据操作语言,对数据库表中进行增删改
DQL 数据查询语言,查询数据库中表的记录
DCL 数据控制语言,创建数据库用户,控制数据库的访问权限
DDL语法
数据库操作
查询所有数据库
SHOW DATABASES; |
查询当前数据库
当不知道自己处在哪里时可以使用
SELECT DATABASE(); |
创建
CREATE DATABASE 数据库名 |
[1] 如果数据存在那么不执行该语句,如果不存在则执行
[2] 指定字符集 ,数据库中utf8一个字符最多3个字节,但有的字符会占4个字节,可以使用utf8mb4
[3] 指定排序方式
写的时候方括号不要带
删除
DROP DATABASE [IF EXISTS] 数据库名 |
[1] 存在则删
使用
USE 数据库名; |
表操作
查询当前数据库所有表(必须在某个数据库中)
show tables; |
查询表结构
desc 表名 |
查询指定表的建表语句
show create table 表名 |
表创建
create table 表名 |
示例
mysql> create table user |
数据类型
tinyint 1b |
字符串类型
char 0-255B 定长字符串 |
日期类型
data 3 YYYY-MM-DD 日期值 |
样例 员工表
create table employee |
修改
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束] |
修改数据类型
alter table 表名 modify 字段名 新数据类型(长度) |
修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束] |
删除字段
alter table 表名 drop 字段名 |
修改表名
alter table 表名 rename to 新表名 |
删除表
drop table [if exists] 表名 |
删除指定表,并重新创建该表
truncate table 表名 |
DataGrip
创建好项目后的链接操作,选择mysql
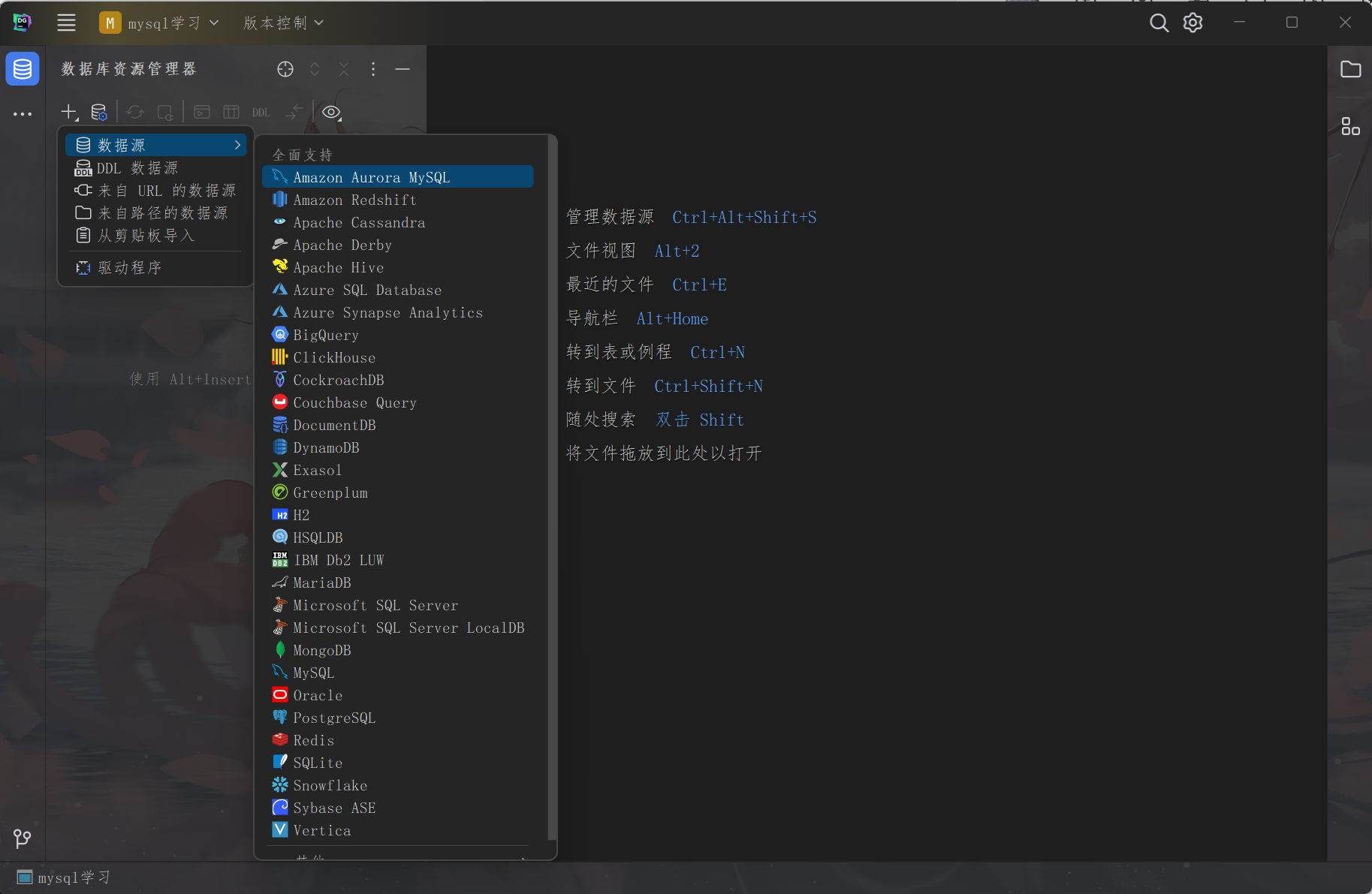
配置链接信息,同时点击下方下载驱动,下载好后test成功即可使用
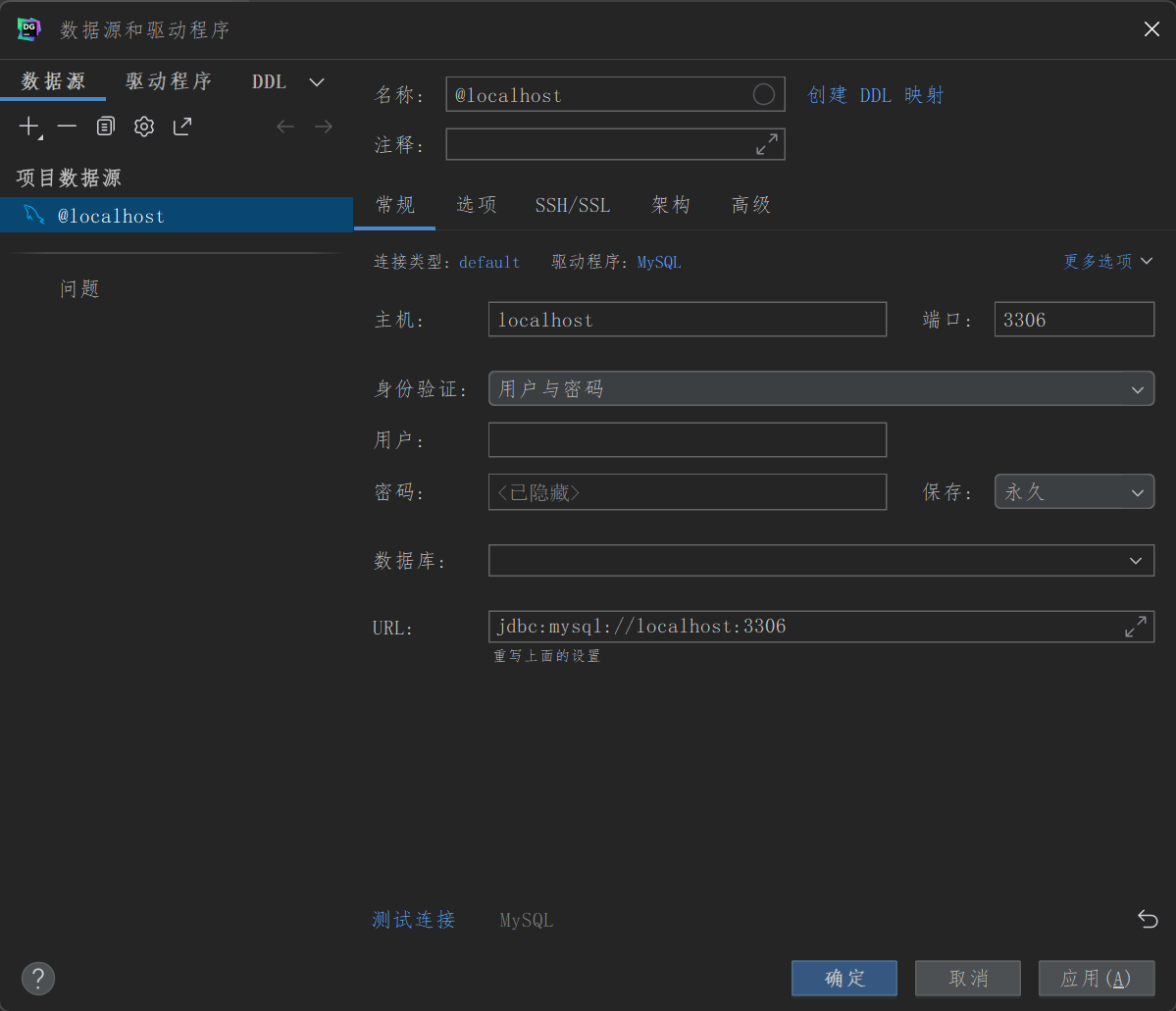
此处选择所有架构,来让所有数据库显示,架构即为数据库,新建数据库时也是选择架构Schema
DML
对数据库的数据记录进行增删改操作
添加数据
给指定字段添加数据
insert into 表名(字段1,字段2,...) values(值1,值2,...) |
给全部字段添加数据
insert into 表名 values(值1,值2...) |
批量添加数据
insert into 表名 (字段1,字段2,...) values (值1,值2,...),(值1,值2,...),... |
insert into 表名 values (值1,值2,...),(值1,值2,...),... |
插入时如果是字符串或者日期应该在引号内
展示数据
在datagrip可以双击表打开,或者使用命令
select * from 表名 |
修改数据
update 表名 set 字段1=值1,字段2=值2,...[where 条件] |
修改语句的条件可以没有,如果没有,则是修改整个表的数据
例
update employee set name='zhangsan' where id=2; |
删除数据
delete from 表名 [where 条件] |
条件没有则删除表里所有数据
delete不能删除某个字段的值,设成null即可
目前已使用的命令集合
show databases; |
DQL
数据查询语言,用来查询表中数据记录
基本查询
表创建以及数据插入
create database dql_study; |
查询多个字段
select 字段1,字段2,... from 表名 |
select * from 表名 |
设置别名
select 字段1 [as 别名1],字段2 [as 别名2],... from 表名 |
去除重复记录
select distinct 字段列表 from 表名 |
条件查询
select 字段列表 from 表名 where 条件列表 |
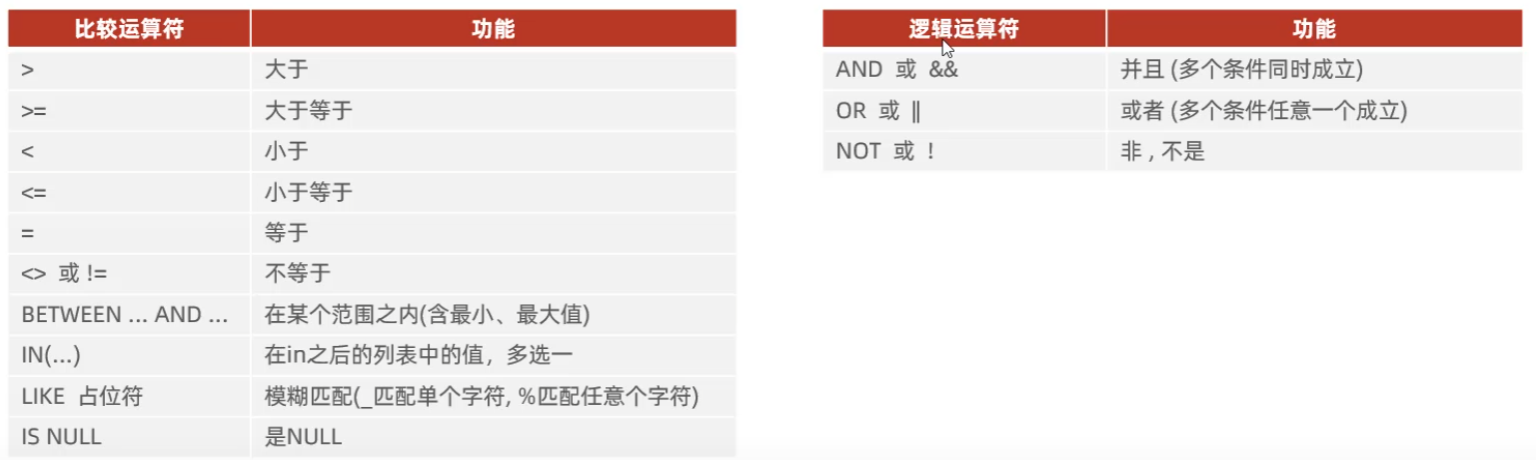
不建议使用&&,||,!,他们在release版本时可能被清除掉
-- 条件查询 |
聚合函数
将一列数据作为一个整体,进行纵向计算
有count,max,min,avg,sum等
select 聚合函数(字段列表) from 表名 |
-- 聚合函数 |
分组查询
select 字段列表 from 表名 [where 条件] group by 分组名 [having 分组后过滤条件] |
where 和 having区别
执行时机: where 是分组之前进行过滤,不满足where条件,不参与分组;
having是对分组之后的结果过滤
判断条件不同: where不能对聚合函数判断,having可以
-- 分组查询 |
排序查询
select 字段列表 from 表名 order by 字段1 排序方式,字段2 排序方式 |
排序方式: ASC 升序(默认)
DESC 降序
-- 排序查询 |
分页查询
select 字段列表 from 表名 limit 起始索引,查询记录数 |
起始索引从0开始
分页查询时数据库的方言,不同数据库有不同实现,mysql是limit
查询第一页可以省略起始索引
-- 分页查询 |
案例
-- 查询年龄为20,21,22,23岁的员工信息 |
执行顺序
from > where > group by > having > select > order by > limit
DCL
数据控制语言,用来管理数据库用户,控制数据库的访问权限
管理用户
查询用户
use mysql; |
创建用户
create user '用户名'@'主机名' identified by '密码' |
修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码' |
删除用户
drop user '用户名'@'主机名' |
use mysql; |
权限控制
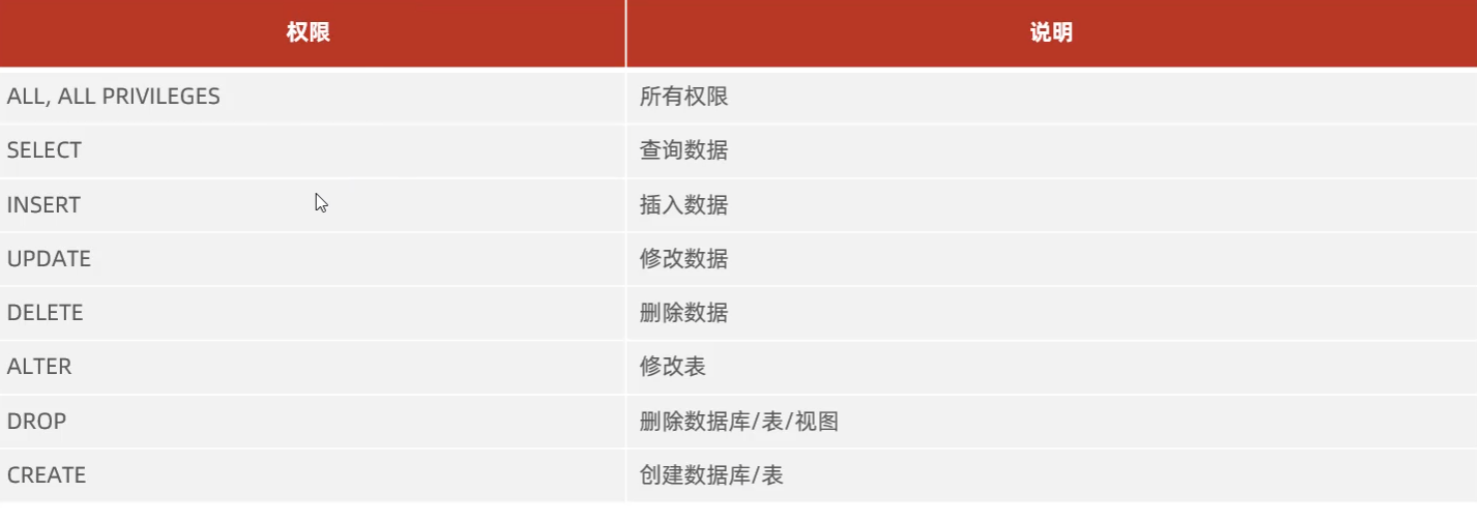
查询权限
show grants for '用户名'@'主机名' |
授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名' |
撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名' |
show grants for 'test'@'localhost'; |
函数
可以直接调用的程序或代码
字符串函数
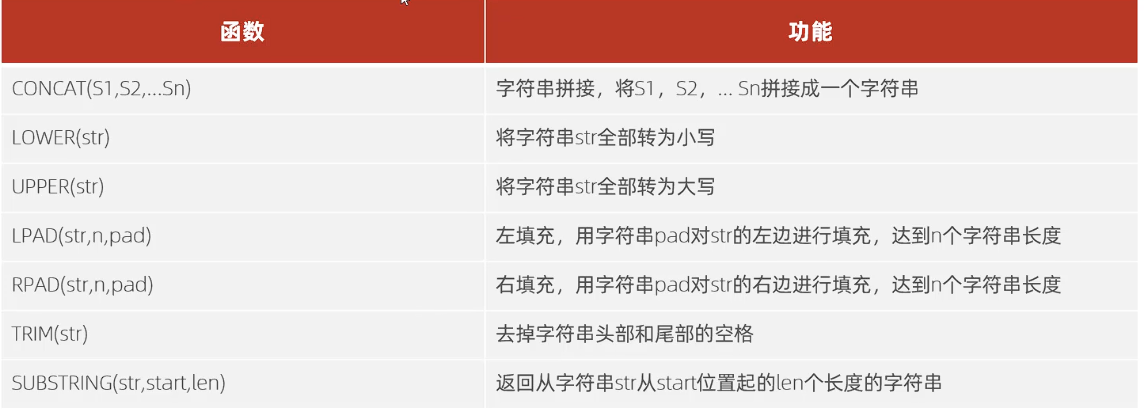
-- 字符串函数 |
唯一要注意的就是substring的起始点
数值函数
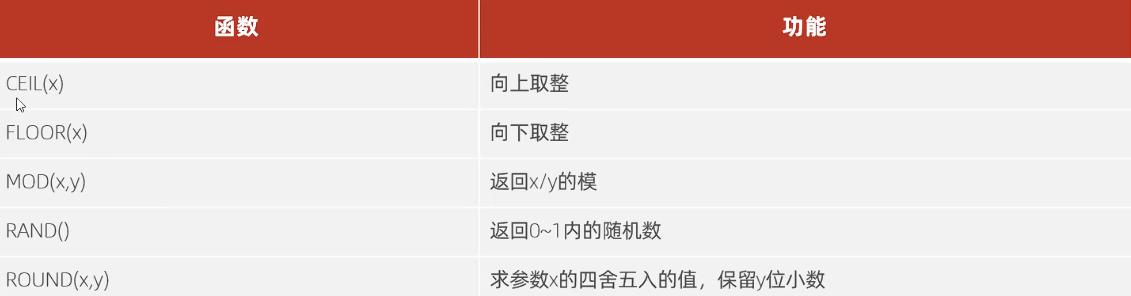
-- ceil |
日期函数
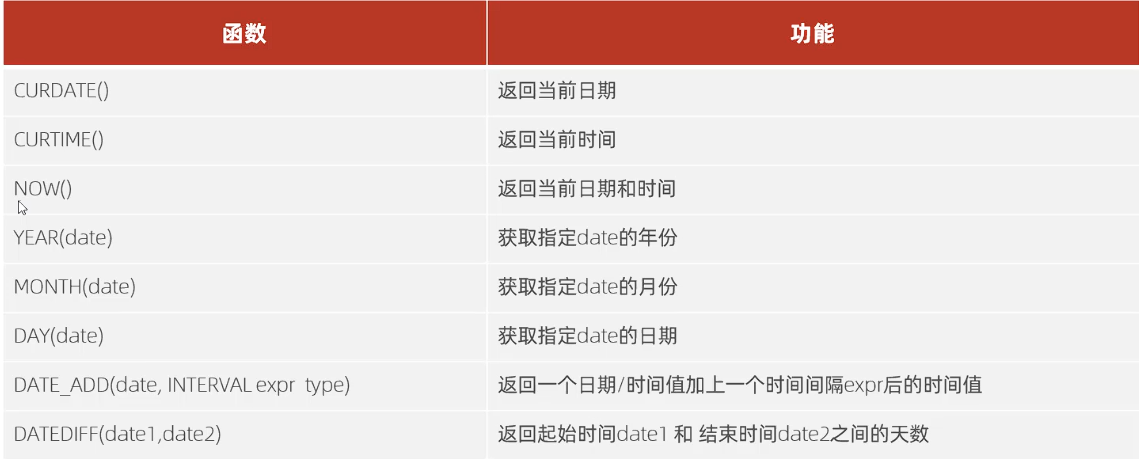
-- 日期函数 |
流程函数
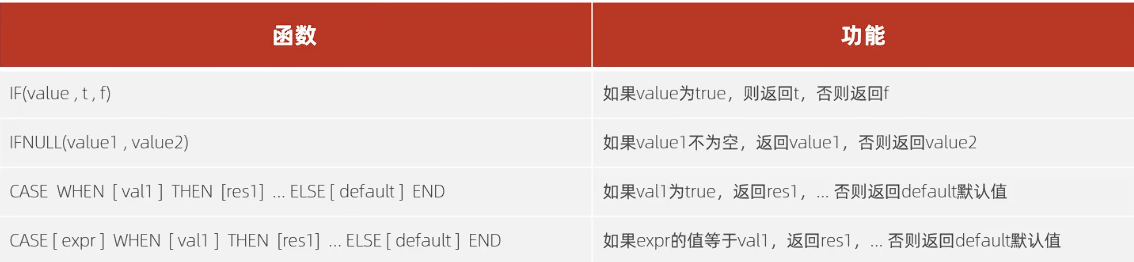
-- 流程函数 |
约束
约束是作用于表中字段上的规则,用于限制存储在表中的数据

use yueshu; |
外键约束
外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性
- 创建表时设置外键
create table 表名( |
创建后设置外键
alter table 表名 add constraint 外键名 foreign key (外键字段名) references 主表 (主表列名)
-- 外键约束 |
删除外键
alter table 表名 drop foreign key 外键名称
外键删除更新行为

alter table 表名 add constraint 外键名称 foreign key (外键字段) references 主表名 (主表字段名) on update 行为 on delete 行为 |
多表查询
多表关系
一对多
多的一方建立外键,指向另一方的主键
多对多
建立一张中间表,至少包含两个外键,分别关联两边的主键
-- 多对多关系 |
一对一
多用于单标拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中
在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一
-- 一对一 |
多表查询
从多张表中进行查询
-- 单表 |
内连接
查询A,B表交集部分数据
外连接:
- 左外连接:查询左表所有数据,包含交集部分数据
- 右外连接:查询右表所有数据,包含交集部分数据
自连接: 当前表与自身的连接查询,自连接必须使用表别名
隐式内连接:
select 字段列表 from 表1,表2 where 条件
显示内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件
外连接
左外连接:
select 字段列表 from 表1 left [outer] join 表2 on 条件 |
右外连接
select 字段列表 from 表1 right [outer] join 表2 on 条件 |
自连接
select 字段列表 from 表A 别名A join 表A 别名B on 条件 |
自连接查询,可以是内连接查询,也可以是外连接查询
-- 自连接 |
联合查询
对于联合查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
select 字段列表 from 表A ... |
去掉all,去重操作
-- 将薪资低于5000的员工和年龄大于50的员工全部查询出来 |
查询的字段必须保持一致
子查询
sql语句中嵌套select语句,成为嵌套查询,又称子查询
select * from t1 where column1 = (select column1 from t2); |
标量子查询
子查询返回的结果是单个值(数字,字符串,日期等)
-- 查询销售部所有的员工信息 |
列子查询
子查询返回的结果是一列
常见操作符:in,not in,any,some,all

-- 列子查询 |
行子查询
查询结果是一行
-- 查询与张无忌的薪资及直属领导相同的员工信息 |
表子查询
返回的是多行多列
-- 表子查询 |
案例
-- ---------------------------------------> 多表查询案例 <---------------------------------- |
事务
一组操作的集合,是一个不可分割的单位,事务会把所有操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败
事务操作
查看/设置事务提交方式
select @@autocommit;
set @@autocommit = 0;提交事务
commit
回滚事务
rollback
简单事务操作
开启事务
start transaction/begin;
提交事务
commit;
回滚事务
rollback;
-- 创建银行账户表 |
事务特性
- 原子性: 不可分割,全部成功或全部失败
- 一致性: 事务完成时,必须使所有的数据保持一致状态
- 隔离性: 保证事务不受外部并发操作影响的独立环境下运行
- 持久性: 事务一旦提交或回滚,对数据库的改变是永久的
并发事务问题

事务隔离级别
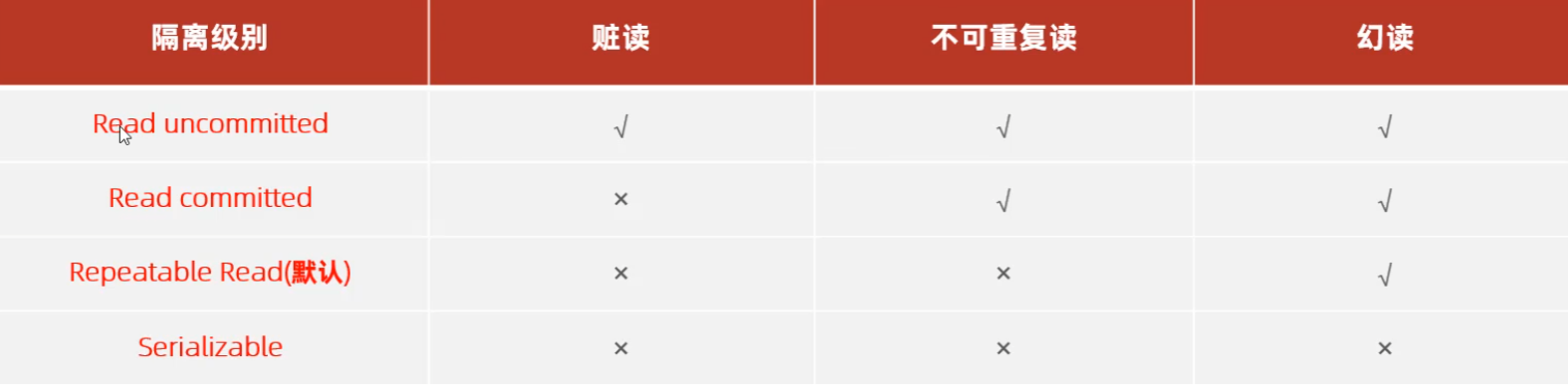
查看事务隔离级别
select @@transaction_isolation |
设置事务隔离级别
set [seesion|gloal] transaction isolation level [read uncommitted | read committed | repeatable read serializable] |
 wechat
wechat alipay
alipay



