linux第一部分,命令操作
| 快捷键或命令 | 作用 |
|---|---|
| ctrl+ alt + t | 打开终端窗口 |
| tab | 命令补全,补全命令,补全目录、补全命令参数 |
| ctrl + c | 强行终止当前命令 |
| ctrl + d | 键盘输入终止 |
| ctrl + s | 暂停命令,任意键继续 |
| ctrl + z | 将当前程序放到后台运行,恢复到前台为命令fg |
| ping + 网址 | 检测网络 |
| ifconfig | 查看网络默认分配地址 |
| clear | 清除界面 |
| ping + 默认分配ip地址 | 检测与路由器连接状况 |
| ping + 127.0.0.1 | 检测与本机连接情况 |
| sudo(获取超级命令权限) apt install(下载安装命令) … | 安装… |
| sudo apt update | 更新软件列表 |
| cat /etc/… | 查看… |
| cat /etc/issue | 查看发行版本 |
| history | 查看历来命令(从你装了这个系统开始) |
| man … | 查看某命令的相关命令及解释 |
| cd / | 切换到根目录,cd用于改变当前工作目录 要加路径 |
| ll | 显示当前目录的文件(附详细信息) |
| ls | 罗列当前目录的文件 |
| pwd | 显示当前工作目录 |
| cd . | 返回当前目录 |
| cd .. | 返回上层目录 |
| cd ~ | 切换的该用户家目录 |
| cd - | 返回上一次的目录cd |
| cd /…/ | 进入…的目录 |
| ls(后面的符号i与cd相同) | 显示指定目录的内容 |
| mkdir xxx | (make directory)在当前目录下创建文件夹,也可一次性创建多个,即mkdir xxx xxx xxx … |
| rmdir xxx | 删除当前目录的xxx文件夹 |
| rm xxx(或者对应路径下的xxx) | 删除当前目录的xxx文件 |
| cp file1 file2 | 将某目录file1文件复制到某目录file2文件下,如果存在file2则覆盖,如果不存在则创建,-r时可以操作文件夹 |
| mv file1 file2 | 将file1移动到file2所在位置,如果在同目录下且file2不存在,则可认为是将file1改名为file2,如果file2不存在则创建文件,如果文件存在则覆盖文件 |
| ln aaa bbb | 硬链接bbb链接到aaa |
| ln /…/aaa bbb -s | 软链接bbb存储指向aaa的路径 |
| echo “aaabbb” > xxx | 把字符串aaabbb写入到xxx文件中 |
| find -name “xxx” | 查找指定xxx名称的文件的路径 |
| chmod xxx file | 数字设定法改变一个文件对三类用户的权限 |
| umask | 查看文件掩码 |
| umask xxxx | 临时修改当前用户文件掩码 |
初步认识linux
网络设置
桥接模式:处于同一个网络,路由器给主机分配一个ip地址也给虚拟机分配一个ip地址
NAT模式:本机虚拟一个路由器,该路由器用来连接虚拟机,即创建了一个内网
内网可以访问外网,外网无法访问内网(一般情况,NAT穿透技术可以实现外网访问内网)
设置静态IP地址
- 选择自动DHCP模式
2.重启网络(网络打开再关闭),检测有无网络
3.查看网络detail信息,记录下来
4.在ipv4分页改为手动
5.填写记录信息,子网掩码设置为255.255.255.0,子网掩码用于获取ip地址的网段,网关填写默认路由地址
6.应用设置,测试网络
远程连接(连接虚拟机)
1.C/S架构,客户端(client)服务器(sever)架构,如果连接虚拟机,服务器就是虚拟机,客户端即远程连接工具所在机器,服务器端需要安装服务端程序(sshd)
$sudo apt install ssh |
$ps -elf|grep sshd |
2.切换到客户端xshell程序,open命令打开会话,新建会话
3.协议选择ssh,主机名为虚拟机静态ip地址
建立一个c/cpp文件并编译运行
$ cd hello.cpp #进入源文件所在目录 |
linux内核
内核(kernel)作用:
1.管理硬件资源
2.为上层应用软件提供了运行环境
系统调用(system calls) 内核对上层应用程序提供的的接口
库函数 对系统调用进行的包装
shell 命令解释器,解析命令,执行命令/脚本,脚本(命令的集合)
用户子系统
用户分类
1.特权用户/root用户 啥都能干
2.普通用户 sudoers 临时拥有一些权限
3.其他用户
查看所有用户命令
$ cat /etc/passwd |
为某用户申请特权
$ sudo useradd xxx |
删除用户及其所拥有文件
$ sudo userdel xxx |
正确创建用户
$ sudo useradd -m -s bin/bash xxx |
切换用户
$su xxx |
banner打印字符串
//一般打印 |
xxx的这种参数一般可放在命令末尾也可以放在主命令后面
文件操作
文件子系统
| 文件名 | 意义 |
|---|---|
| bin | binary 可执行程序 |
| dev | device 设备文件 |
| home | 普通目录家目录的根目录 |
| root | root用户的家目录 |
| sbin | system binary 和系统相关的可执行程序 |
| var | variable 经常发生变化的文件(e.g. 日志文件) |
| etc | 配置文件 |
| lib | 库文件 |
| proc | process 进程映射文件 |
| usr | 普通用户能够访问的文件 |
文件夹与文件操作
$mkdir xxx |
在ll或者ls - l显示文件时
第一列如果前缀时dir则表示文件夹,如果是-开头则表示普通文件,l开头则表示符号链接,c代表字符设备(键盘),b代表块设备(硬盘),p代表管道文件(进程之间进行通信的文件),s表示套接字文件(网络通信)
后面跟着的w,r,e分别代表write,read,execute,表示普通用户能够行使的权限,总共出现三次即三组,第一组表示自己的权限,第二组表示同组的其他成员的权限,第三组表示其他组成员的权限,例如 drwxr-xr-x
第二列 硬链接个数
第三列 用户名称
第四列 用户所属组名
第五列 文件大小 单位比特byte
第六列 最近修改时间
最后一列 文件名称
通配符(wild card)
| 通配符 | 意义 |
|---|---|
| * | 可以匹配任意多个字符(包括0个字符) |
| ? | 可以匹配任意一个字符 |
| […] | 匹配这个集合(即这个括号内)的任意一个字符 |
| [!…] | 匹配集合外的任意一个字符 |
| [0-9],[a-z],[A-Z],[A-Za-z] | 匹配内部的任意一个字符 |
cp(copy)
//可以复制一个文件或一个文件夹 |
mv
//将一个文件移动到另一目录下 |
rm
//删除文件或者删除文件夹(与rmdir不同,既可以删除空文件夹也可以删除有文件的文件夹) |
链接
硬链接
目录本质也是一个文件
通过ls - la可以看到开头的两个文件分别是 . 和 ..
目录会存储一些目录项,. 和 .. 就是目录项,分别指向当前目录和上级目录,目录项以链表进行链接,每个节点就是一个目录项(entry),目录中的普通文件不算目录项
通过目录项可以直接访问某个目录,就称为硬链接
如果想在一个目录中添加或删除目录项,该用户需要拥有该目录的写权限
一个普通文件的硬链接数默认为1
软链接(符号链接)
某个文件存储的是一个路径,这条路径指向了一个目录,这个间接访问目录的方式就成为软链接
符号链接类似与指针,和windows的快捷方式
ln(link)
//创建链接 |
查找文件
locate
//全盘查找某文件 |
which(常用)
//定位一个command(可执行程序) |
find
//在该目录下进行搜索,如果有子目录也会在子目录中进行搜索, 可以使用通配符进行查找 |
权限
一般用linux执行.py文件时是没有足够权限的
在执行该文件时提示权限不足
Permisson Denied
chmod(change mode)改变权限
//文字设定法 |
umask(文件掩码)
文件掩码指的是在创建文件(0666)或目录时(0777)在全部权限中要去掉的一些权限
//获取文件掩码 |
查看文件
文件描述符(一般为非负整数)
stdin 标准输入 0
stdout 标准输出 1
stderror 标准错误输出 2
‘>’ 标准输出重定向(可以认为是c++的输入)
’<‘ 标准输入重定向(可以认为是c++的输出)
2 > 标准错误重定向(2就是strerror)
‘>>’ 标准输出重定向(追加方式)
cat(查看文件内容)
//查看一个文件的内容(速度慢,因为和strcat一样是在输出流直接拼接内容) |
echo(打印一行文本)
//打印xxx |
head(显示文件的头几行信息)
//默认输出10行 |
tail(显示文件的后几行信息)
//默认输出10行 |
more/less(单页浏览文件)
//每次查看文件的某页 |
正则表达式
sort
//对文件内容进行排序(以行为单位) |
uniq(unique)
//去重连续重复的几行 |
对一个文件操作得到排序且没有重复元素的文件
sort sort.txt > sortt.txt;uniq sortt.txt > sort.txt;rm sortt.txt |
xargs
// | 管道连接两个命令,管道相当于一个缓冲区,通过第一条命令将结果输送到管道中,然后对管道的内容执行第二条命令,xargs是对内容每一行执行一次命令2 |
file
//得到一个文件的信息(比ls-la更详细) |
wc(what count)
//记录文件中的行数,字节数,单词数 |
iconv
//修改字符集 |
正则表达式
基本单位:普通字符,转义字符,’.’,(任意一个字符),[] 集合(只要集合里的一个元素能匹配上就是能匹配 ),()这个整体作为基本单位
基本操作:1.连接:ab
2.重复(必须是连续的):’?‘ 表示重复1次或0次
’+‘ 表示重复一次或多次
‘*’ 表示重复任意次数
{m,n}表示重复m-n次,m和n可以有一个没有,m没有可以认为最多重复n次,n没有可以认为至少重复m次
{n}表示连续出现特定n次
[ ^abc]匹配任意字符,但不包含a,b,c
特殊符号:
^行首 “^abc”
$行尾 “abc$”
\<词首 “\<a”
\\>词尾 "a\\>"
gerp(搜索文件内容)
//globally regex(regular experssion) print |
alias
alias//别名 |
打包和压缩
//打包 |
scp
df(disk full查看磁盘状态)
-h增加可读性 |
du(disk used查看磁盘使用情况)
du /.../ 查看某目录下的使用情况,默认为当前目录 |
scp(s_cp远程拷贝secure copy)
//在网络上传下载 |
上述操作每次操作时都需要验证用户密码,使用密钥后可以跳过该过程
ssh-keygen密钥
产生密钥 |
git仓库
修改远程仓库过程 |
代码编译
编辑器
vim
vim三种模式 |
设置vim配置文件
配置文件类似于预处理
1.在家目录下创建.vimrc文件
2.打开.vimrc文件
常用配置命令
syntax on//语法检查 |
vimtutor vim练习手册
编译工具链
两种大编译环境
ide: 集成开发环境(常用于windows),例如vs,clion,eclipse,xcode
sdk(常用于linux, 全程software development kit,软件开发工具或编译工具链)
sdk阵营一: gcc
sdk阵营二: clang
gcc -v 查看gcc版本 |
一个程序从创建到可执行的过程
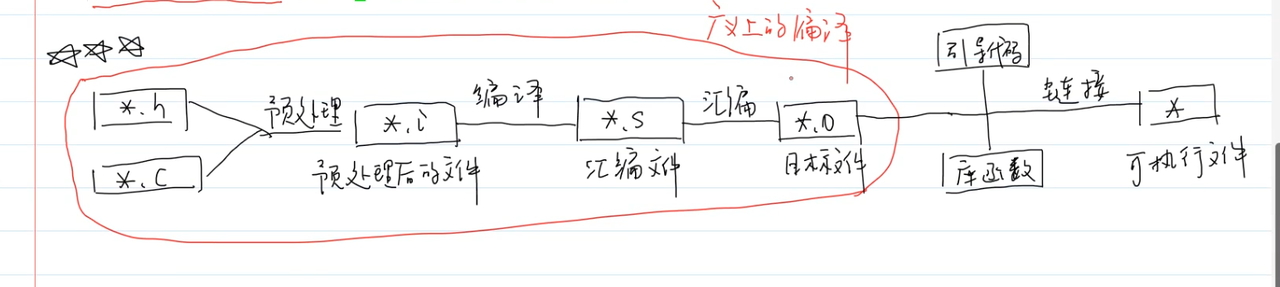
预处理
预处理文件常以.i结尾 |
源代码
|
生成预处理文件
$gcc -E define.c -o define.i |
文件内容
...//以上省略各种预处理代码 |
假设源代码将#if 0改为#if N
|
因为N是不存在的
所以生成的预处理文件会如此
//最终代码
int main()
{
printf("hello world");
return 0;
}而如果使用命令
$gcc -E define.c -o define.i -D N //-D为用命令宏定义了N,让N存在
则生成的预处理文件
//最终代码
int main()
{
printf("Hello World");
return 0;
}- 用命令进行宏定义,方便程序员为不同平台不同客户生成不同代码
- 另一种宏开关
用法:当某个头文件不存在时可以用这种办法自己解决
//进行定义接口
...
...
编译
作用:将c语言代码编译成汇编代码
两种形式
gcc -S xxx.i -o xxx.s //生成汇编文件 |
源代码
|
生成的汇编代码
.file "hello.c" |
上世纪70年代最常用cpu 8086
信息
x86架构 数据总线16b,地址总线20b |
汇编转二进制
as命令
AS - the portable(可移植) GNU assembler(汇编). |
转换命令
as hello.s -o hello.o |
生成的目标文件目前不能直接执行,通过nm命令可以列出所有符号
nm hello.o |
广义的常用的生成命令(从.c文件一键生成到.o目标文件)
gcc -c hello.c -o hello.o |
反编译
objdump命令
命令使用
objdump hello.o -d test.o |
接着就会在控制台直接显示所有内容
|
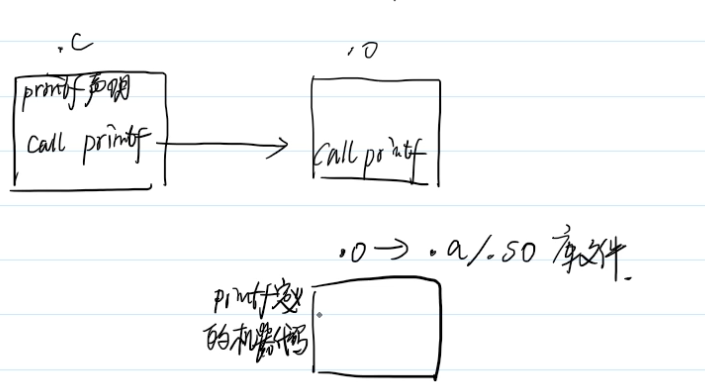
链接
作用:把函数的名字换成地址
ld命令可以进行链接,但不推荐,可能一个函数里调用了另一个函数,这样用ld进行链接会很麻烦
简便做法
gcc命令 不加任何参数,间接调用,就可以把文件的各个函数链接起来
gcc hello.o -o hello |
反汇编hello文件
0000000000201010 B __bss_start |
发现所有函数都找到了对应的地址
执行可执行程序
只要当前用户对文件有x权限即可执行
通过./filename执行可执行程序
库文件
即公用的工具,轮子,是一种特殊的.o文件,他人写好的并且公开发行的,自己拿来用
库文件创建过程
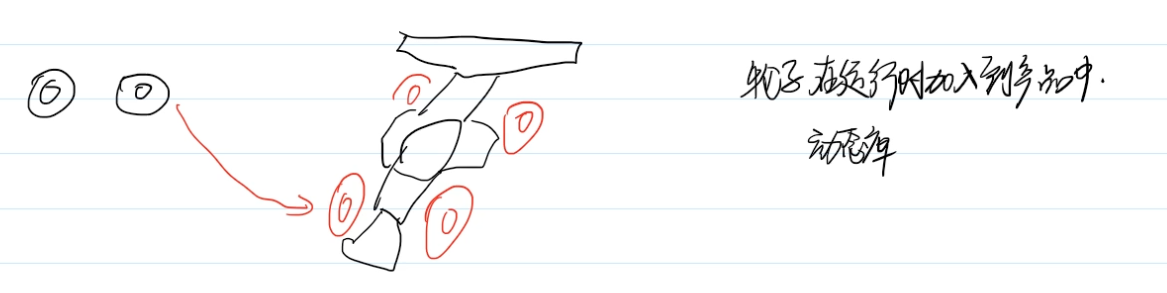
静态库和动态库
静态库:轮子打包到产品中,比喻:家用汽车在生成时就已经组装到车里了,一般情况下不会改变

动态库:在运行的时候轮子才会组装起来,比喻:比赛时用的汽车,例如F4赛车,在赛场上需要跑起来时才会组装上
对比:
静态文件比较大,动态库在运行时才会组装,动态库更加小一些
部署起来静态文件更加容易
动态库更加容易升级,因为轮子换起来更加方便,静态库轮子不方便更换
一般情况下,gcc生成的目标文件都是调用的动态库,加上参数-static调用静态库,根据ldd命令查看文件属性可知.so为动态库文件, .a为静态库文件
生成静态库
当我们调用一个只声明的函数时
|
编译为test.o的目标文件是可以通过的,但是通过gcc进行链接操作时出现了问题
test.o:在函数‘main’中: |
此时我们再编译一个add.c文件
int add(int lhs,int rhs) |
编译同样可以通过,但进行gcc链接操作也出现了问题
(.text+0x20):对‘main’未定义的引用 |
- test.o缺少了add函数的地址,add.o缺少了main函数的地址
接下来我们手动链接test和add
gcc test.o add.o -o test |
发现可以通过,且输出
add(3,4) = 7 |
整个过程简略图

如何将add.o文件变为共享库
生成目标文件
$gcc -c add.c -o add.o
将目标文件打包成静态库文件
$ar crsv libadd.a add.o
生成了一个以libadd为前缀以.a为后缀的静态库文件
将文件移动到系统搜索目录中 (/usr/lib 切换为root用户)
$sudo cp libadd.a /usr/lib
检查此时是否已经复制到了当前目录中

此时重新生成test目标文件
gcc test.o -o test -ladd
你的库叫什么名字在-l后面就加什么名字且不带空格查看是否成功

配置代码环境
vimplus
vscode
vscode环境配置详情见vscode远程连接linux环境配置 | 涅槃豆の博客
动态库链接
- 先把原先的add.c和test.c复制到dynamic文件夹中,进行我们动态库链接的热身

生成test.o目标文件
将add.c编译成目标文件
(动态库的文件在运行时才会加载,运行时会存储在栈和堆中间的一部分区域中,称为共享库映射区)
gcc add.c -o add.o -fpic |
打包成库文件
gcc -shared add.o -o libadd.so
lib为固定前缀,so为固定后缀
将生成的libadd.so移动到/usr/lib目录中

检查系统目录是否存在该文件
编译为可执行文件时加上-l参数(如果生成的还是静态库链接文件记得删除掉/usr/lib中的libadd.a文件)
gcc -c test.c -o test -ladd
通过ldd命令可以查看链接情况

如果此时删除 libadd.so,是没办法运行的,而再把so文件放回去,又可以运行了
软链接 符号链接
软链接实际上就像快捷方式一样,里面的某个字符串存储了真实文件的路径
在动态库文件需要更新时,可以不用删除lib目录下对应的so文件,而是将so文件改造为软链接的方式,链接到新版本的动态库文件

通过ln命令进行软链接
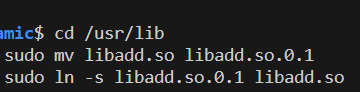
此时我们作为作者更新了我们的add.c源文件
int add(int lhs,int rhs) |
再重新进行生成动态库文件的操作
$ gcc -c add.c -o add.o -fpic |
重新进行软链接操作
%cd /usr/lib |
再次执行test可执行文件
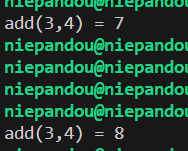
如果需要回滚版本只需要重新进行软链接
gcc其他选项
-D xxx 用命令宏定义一个xxx变量,相当于在代码内部首行添加一个#define xxx
-I /xxx/xxx 增加一个头文件搜索目录
编译优化
-O0 不优化
-O1
-O2
-O3 1->3优化越来越深
gdb
调试
gdb和vs的调试很类似,但多了一种类似黑匣子的功能,可以记录信息
man的描述
gdb - The GNU Debugger |
gdb使用时建议不要开优化,因为优化后会修改最终运行时的代码,调试时的汇编代码可能和源文件差别很大
因此编译时需要加上两个参数
gcc filename -o xxx -O0 -g (-g是记录调试信息)
创建一个用于调试的代码
|
编译时记得加上参数
gcc test.c -o test -O0 -g |
- 此时我们使用gdb命令即可进入调试
gdb test |
- 此界面使用list可以默认显示10行代码
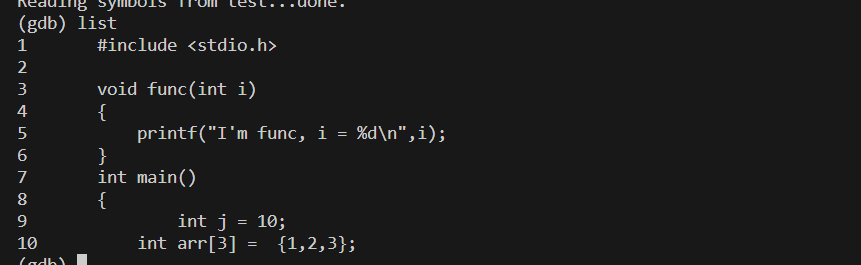
- 再输入list进入下一页
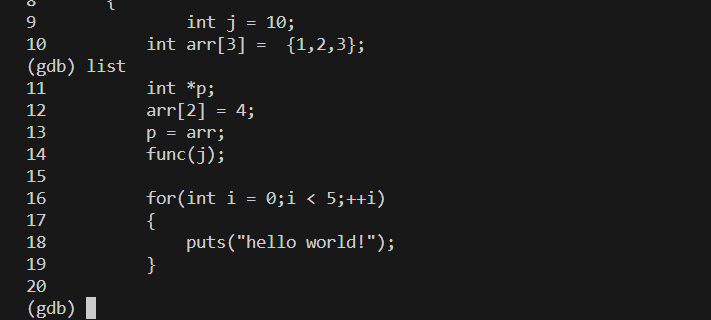
- 输入list1即可回到首行
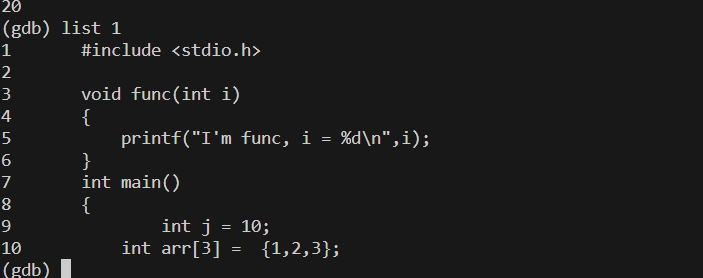
输入l也和list效果相同
- 如果一个程序有多个源文件,也可以指定是哪个文件,比如要查看test.c文件的第一行
输入 l test.c:1
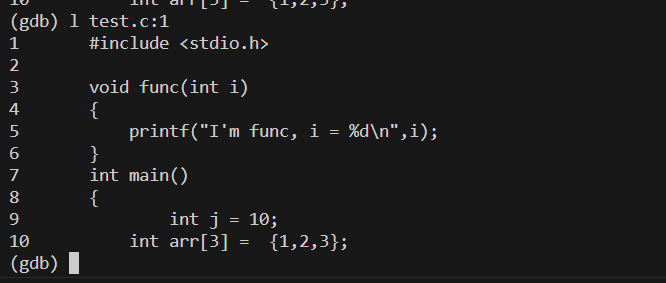
- 同样如果要找某个函数也可以做到,比如要找到main函数
输入l test.c:main
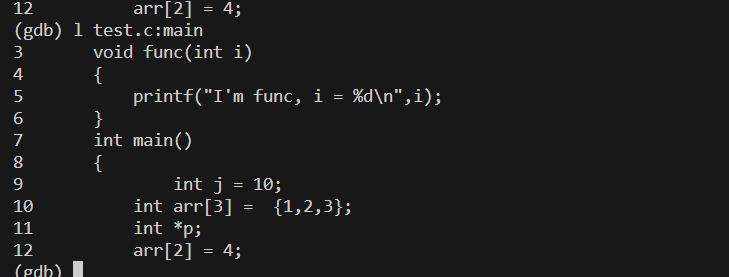
- 如果要运行程序就输入 run或者r
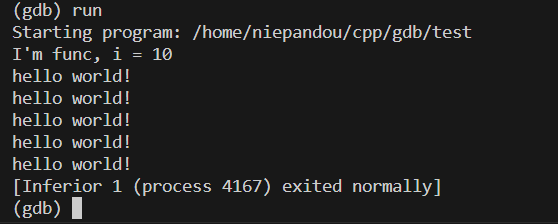
- 打断点的方法 break或者b 同样可以指定行或者函数

在打完断点之后,发现不是一次运行完了

现在我们可以选择进行单步调试,也可以选择输入continue运行到下一个断点

进行单步调试可以输入next或者n或者 step或者s

此时我们发现他进入到了printf.c文件中,虽然没有找到,输入finish可以运行到printf函数运行执行完毕
 再输入next刚好跳出func函数回到main函数里面
再输入next刚好跳出func函数回到main函数里面

如果我们想在运行时删除掉某个断点,则可以用到delete命令,输入delete+空格+对应断点编号即可,而输入delete是删除所有断点
info break或者ib可以查看某行的断点信息,以及相应的命中次数

ingnore +空格+ 编号+ 次数 ,意味着忽略某号断点多少次
在gdb查看监视
输入print + 对应变量名可以查看变量数据
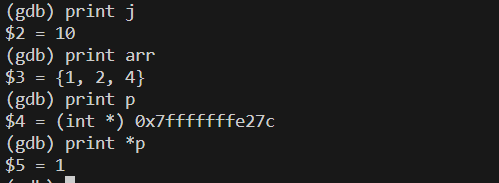
也可以进行对应计算
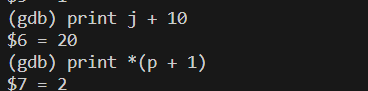
用print显示会有些麻烦 ,而用display加变量名可以在运行时一直显示
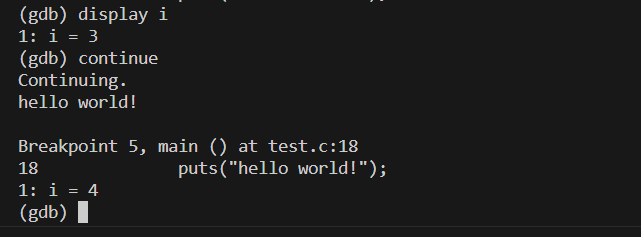
info display可以查看监视信息,从而得知显示的变量的编号
再输入undisplay + 编号即可不再显示该变量
在gdb中查看内存
需要使用x命令,因为命令很复杂我们可以用help查看如何 使用

(gdb)x/FMT ADDRESS |
- count代表要看多少单位
- letter1选择相应格式o,x,d,u,t,f,a,i,c,s,和printf格式输出类似
- letter2选择单位大小b,h,w,g分别为1b,2b,4b,8b
例如我们要查看arr数组内存时
(gdb) x/3tw arr |

- 此时我们也可以通过内存地址查看系统是大端存储(低字节高地址)还是小端存储(低字节低地址)
(gdb)x/4tb arr |

发现1存储在低地址,所以是大端存储
如果感觉不明显可以修改数据然后查看

此时很明显看到高位存储在低地址,确定是大端存储
检查崩溃程序
黑匣子->core文件,存储了程序崩溃时刻内存的堆栈情况
例如我们创建一个必定崩溃的代码
|

编译也可以通过
运行时发现,发生段错误,也就是指针指向出错了

此时发现目录下多了一个core文件

如果没有生成,可以按以下步骤操作
查看core文件可以创建多大
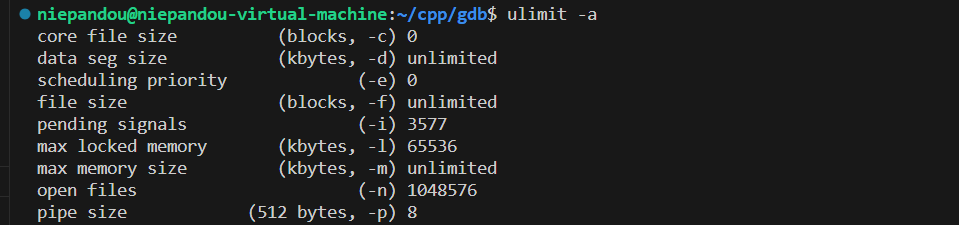
如果core文件大小为0,根据core文件参数,目前显示是-c
则我们输入以下命令(该修改只是暂时的,下次重新进入系统会恢复默认)
ulimit -c unlimited

发现已经修改成功为unlimited,并再次执行代码查看目录是否有core文件

如果还没有生成
切换管理员 su root
输入以下命令 echo core > /proc/sys/kernel/core_pattern

退回到当前用户 exit
再次执行代码并查看是否有core文件

如果core文件生成成功,我们就可以通过gdb查看他是什么时候出错了
$gdb ./filename core |
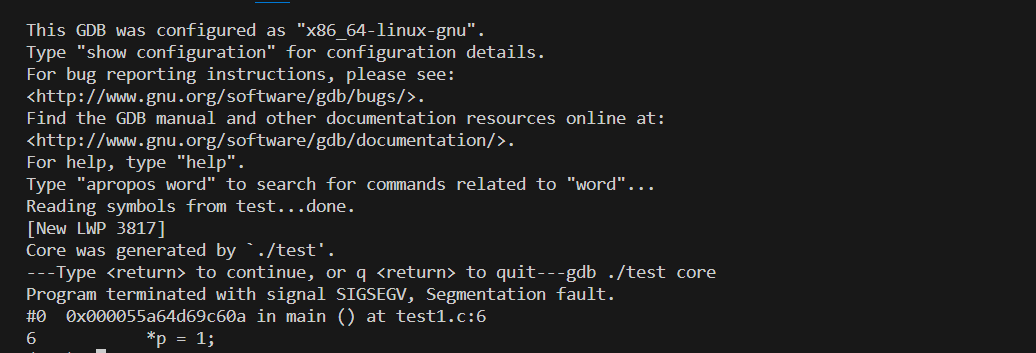
我们再测试另一种情况,并通过gdb查看是哪里出错
void func(int i) |
编译成功后运行

通过gdb查看是哪里出错

发现第三行出错,栈爆了
gdb加命令行参数
过去的c语言main函数中都有两个参数argc和argv[ ]
|
我们可以在编译运行后查看argc和argv都是什么

当我们再运行时添加一些东西时,args和argv的值就会发生变化

也就是说args记录了argv数组有几个元素,argv数组记录了各个参数
如果用gdb去启动

使用set命令可以为其添加参数(非覆盖)

Makefile
makefile增量编译
如果要编译一个系统需要很长时间,且这段时间程序员因为系统cpu等硬件正在满负载工作无法做任何事情,因此需要增量编译来减少编译浪费时间
增量编译首先要维持一种”目标-依赖”关系,构成树的结构,改变某个节点只会影响他的子树
makefile的实现
文件名必须是Makefile/makefile
规则的集合:由目标文件的名称,依赖文件的名称,命令,分号作为目标和依赖的分隔符

把最终要生成的文件作为第一个规则
- 创建main.c和add.c文件
|
int add(int lhs,int rhs) |
在该目录下生成makefile文件并编辑(注意分号分隔符,和命令需要tab键按下后编辑)
main:main.o add.o
gcc main.o add.o -o main
main.o:main.c
gcc -c main.c -o main.o
add.o:add.c
gcc -c add.c -o add.o保证文件的格式都是正确之后,输入make命令,发现需要生成的文件都生成了

当源文件比目标文件修改时间要新的话,再使用make命令就会进行增量编译
比如我修改了add.c

使用make命令,会发现add.o

如果要执行特定指令 可以在make后加上对应目标文件,例如 make main.o则是以main.o作为目标起点
伪目标
特点:目标不存在,执行命令是不会生成目标文件的
因为目标不存在,所以导致了每次make都一定执行他的命令
修改makefile文件,添加一个clean目标文件
解释原理:原先的main和main.o,add.o都有对应的依赖文件,形成的树结构如下
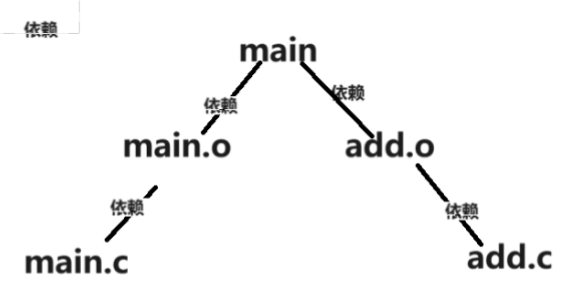
而clean没有依赖文件,当输入make clean以clean为起点时
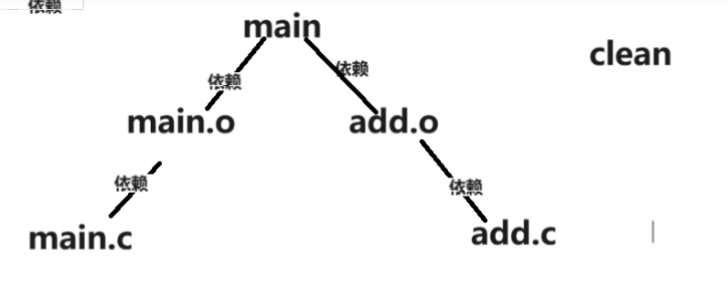
clean只会执行属于自己的命令,没有依赖文件也就是没有子树所以main,main.o,add.o的命令都不会执行
main:main.o add.o |
在make时加上clean,每次都会执行对应命令

全量编译
可以在makefile文件中加入一些东西
main:main.o add.o |
rebulid的依赖文件为clean和main,先依赖的clean因此会先执行clean的命令,将main.o,add.o和main都删除,然后再执行main命令,又依次生成了main.o,add.o,main

这样的删除全部生成文件然后又重新生成的操作成为全量编译
为了makefile规范,我们通常在伪目标之前声明一下
main:main.o add.o
gcc main.o add.o -o main
main.o:main.c
gcc -c main.c -o main.o
add.o:add.c
gcc -c add.c -o add.o
clean:
rm -f main.o add.o main
rebuild:clean main.PHONY就是声明clean和rebuild是伪目标,没有任何作用
变量
makefile原内容
main:main.o add.o |
自定义变量: 变量名:=值 (在makefile中,变量中所有值都是字符串类型)
引用变量: $(变量名)
使用自定义变量后就可以更改原来的内容了
OUT:=main #定义变量
OBJS:= main.o add.o
$(OUT):$(OBJS)
gcc $(OBJS) -o main
main.o:main.c
gcc -c main.c -o main.o
add.o:add.c
gcc -c add.c -o add.o
clean:
rm -f $(OBJS) $(OUT)
rebuild:clean main预定义变量:预先就有值的意思
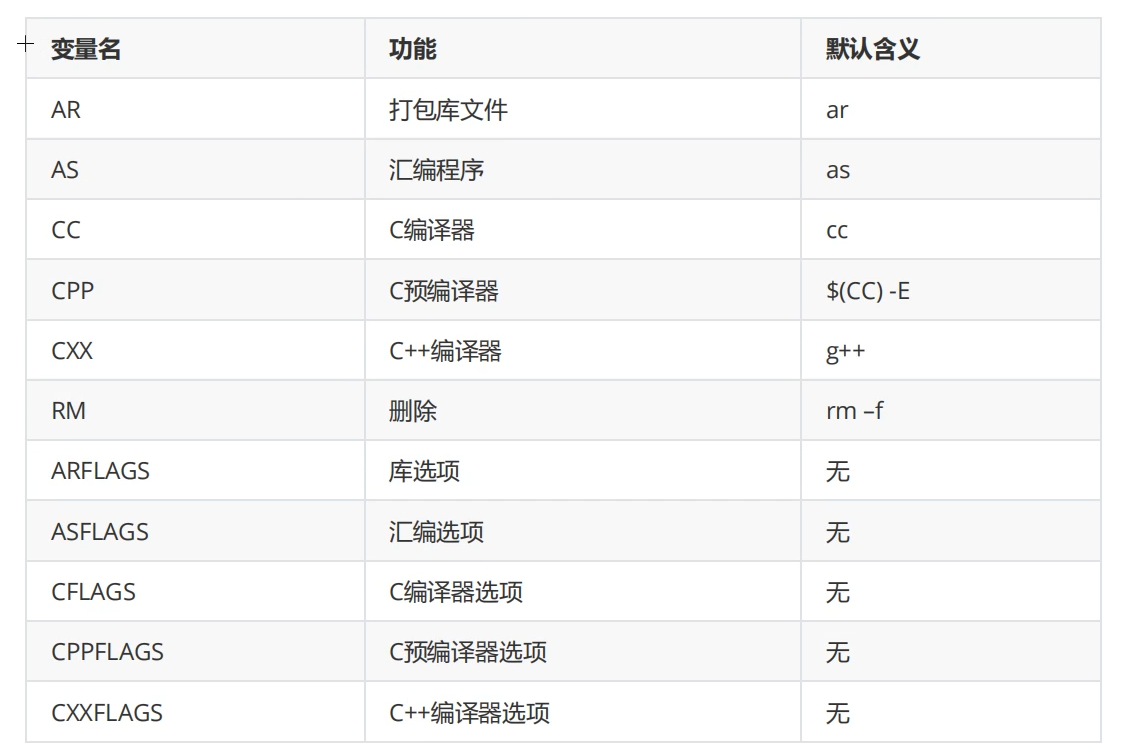
根据预定义变量我们可以把gcc替换成$(CC),rm-f替换成$(RM)
OUT:=main
OBJS:= main.o add.o
$(OUT):$(OBJS)
$(CC) $(OBJS) -o main
main.o:main.c
$(CC) -c main.c -o main.o
add.o:add.c
$(CC) -c add.c -o add.o
clean:
$(RM) $(OBJS) $(OUT)
rebuild:clean main使用make rebuild发现使用的是cc而不是gcc

我们可以修改预定义变量的值
CC:=gcc

自动变量:同一变量名根据规则变化自动变化,类似auto
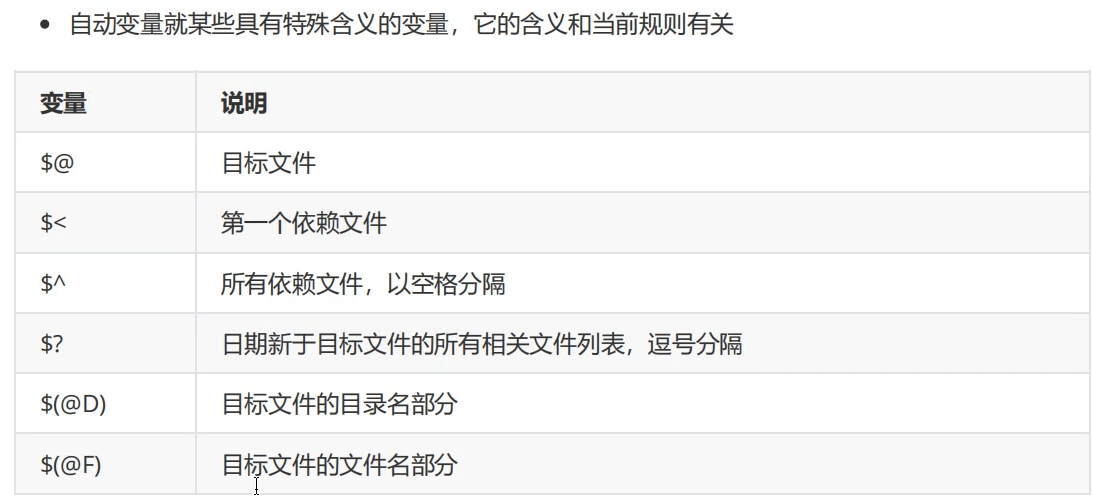
根据表格我们可以如此修改
OUT:=main
OBJS:= main.o add.o
CC:=gcc
$(OUT):$(OBJS)
$(CC) $^ -o $@
main.o:main.c
$(CC) -c $^ -o $@
add.o:add.c
$(CC) -c $^ -o $@
clean:
$(RM) $(OBJS) $(OUT)
rebuild:clean main
用%字符管理格式关系
通过观察我们可以发现main.o和add.o的目标文件,依赖关系,命令格式是完全相同的,我们可以用%来合并为一个,%负责从上一个规则的依赖关系的字符串中把数据匹配出来
我们可以如下修改
OUT:=main
OBJS:= main.o add.o
CC:=gcc
$(OUT):$(OBJS)
$(CC) $^ -o $@
%.o:%.c
$(CC) -c $^ -o $@
clean:
$(RM) $(OBJS) $(OUT)
rebuild:clean main%.o第一次匹配到的是main.o,此时的%代表的就是main,执行完这一个规则后再次匹配,匹配到add.o,此时%就是add,如此往复知道没有可匹配的结束这一整个大规则
如果我们想要新增一个函数在main中调用
main.c
int add(int,int);
int sub(int,int);
int main()
{
printf("add(3,4) = %d\n",add(3,4));
printf("sub(3,4) = %d\n",sub(3,4));
return 0;
}sub.c
int sub(int lhs,int rhs)
{
return lhs - rhs;
}此时我们直接在makefile文件中的OBJS变量中加上sub.o即可
执行make并运行main


可以看出makefile方便了我们程序员进行编译的操作
内置函数
如果觉得增量编译一个.c文件需要修改一行还是很麻烦,那么还有我们的内置函数
wildcard通配符
从当前目录所有文件中取出符合要求的文件名
因此我们可以创建一个变量,通过通配符获取当前目录所有的.c文件
SRCS:=$(wildcard *.c)
如果相要检查是否完全获取到,可以通过伪目标的命令来查看
all:
echo $(SRCS)OUT:=main
SRCS:=$(wildcard *.c)
OBJS:= main.o add.o sub.o
CC:=gcc
$(OUT):$(OBJS)
$(CC) $^ -o $@
%.o:%.c
$(CC) -c $^ -o $@
clean:
$(RM) $(OBJS) $(OUT)
rebuild:clean main
all:
echo $(SRCS)通过make all命令检查

patsubst(pattern substitute)模式匹配
类似一种函数的形式,将指定变量中.c后缀的替换成.o后缀赋值到当前命令中
OBJS:=$(patsubst %.c,%.o,%(SRCS))
此时即使我们的代码有调整,有新增的.c文件,makefile也不需要修改任何东西
我们只需要使用make命令即可完成之前的一系列操作
最终版本
OUT:=main |
make命令

第二版makefile
之前的makefile最终都是只为编译一个最终的目标文件
而当我们正常使用时,一般都会想每个代码分别编译运行,让每个代码单独编译链接
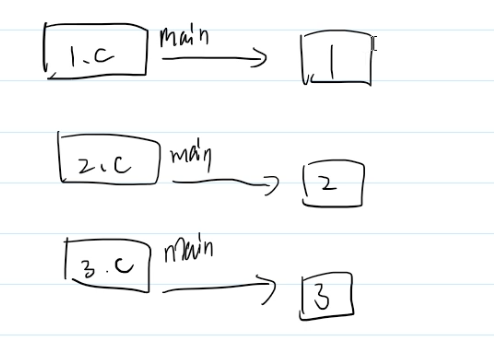
最大的区别是我们可以通过伪目标一次生成不同的目标文件,通过make all实现一次编译多个文件
SRCS:=$(wildcard *.c) |
此时我们发现3个分别输出1,2,3的文件一次编译生成了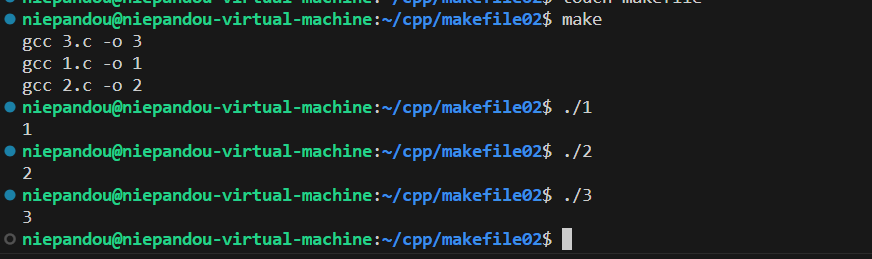
如果说我们代码的源文件在不同目录下,例如存放makefile在根目录下,源代码在根目录的src目录下,比如我们在wildcard下做如此操作即可
SRCS:=$(wildcard src/*.c)
 wechat
wechat alipay
alipay






